
Web Scraping ist die automatisierte Extraktion von Daten von Websites, oft verwendet, um Informationen für verschiedene Zwecke wie Preisvergleiche, Stimmungsanalysen oder Datenaggregation zu sammeln.
Während Web Scraping in einigen Fällen nützlich sein kann, kann unbefugtes Web Scraping die Leistung von Websites negativ beeinflussen, sensible Informationen stehlen und Urheberrechts- sowie Datenschutzgesetze verletzen.
In diesem Blogbeitrag werden wir die Wichtigkeit der Verhinderung von unbefugtem Web Scraping untersuchen und verschiedene Strategien zum Schutz Ihrer Website und Daten diskutieren.
Verständnis von Web Scraping
Definition und Zweck des Web Scraping
Web Scraping ist eine Technik, die das Extrahieren von Informationen von Websites mit automatisierten Werkzeugen oder Skripten umfasst, typischerweise für Datenanalyse oder andere datengesteuerte Anwendungen.
Dieser Prozess kann für Unternehmen und Forscher nützlich sein, die spezifische Informationen schnell und effizient über mehrere Websites hinweg sammeln möchten.
Häufige Werkzeuge und Techniken für Web Scraping
Es gibt viele Web-Scraping-Tools, von einfachen Browsererweiterungen bis hin zu komplexeren Bibliotheken und Frameworks. Zu den beliebten Web-Scraping-Tools gehören Beautiful Soup, Scrapy und Selenium.
Diese Werkzeuge verwenden eine Kombination von Techniken, wie HTTP-Anfragen, HTML-Parsing und Navigation im Document Object Model (DOM), um Daten von Websites zu extrahieren.
Rechtliche und ethische Aspekte des Web Scraping
Obwohl Web Scraping wertvolle Daten liefern kann, kann es auch rechtliche und ethische Bedenken aufwerfen. Probleme wie Urheberrechtsverletzungen, Datenschutz und Verletzung von Nutzungsbedingungen können durch unbefugtes Web Scraping entstehen.
Es ist wichtig, sich dieser Bedenken bewusst zu sein und sicherzustellen, dass Ihre Web-Scraping-Aktivitäten ethisch und rechtlich korrekt durchgeführt werden. Wir haben einen detaillierten Blogbeitrag darüber, ob Web Scraping ethisch ist oder nicht.
Häufige Anzeichen von Web Scraping
Plötzlicher Anstieg der Serverlast und Bandbreitennutzung
Web Scraping kann zu einem plötzlichen Anstieg der Serverlast und Bandbreitennutzung führen, da Scraper in kurzer Zeit eine große Anzahl von Anfragen stellen können. Dies kann zu langsamerer Website-Leistung und erhöhten Hosting-Kosten führen.
Ungewöhnliche Muster von User-Agent-Strings
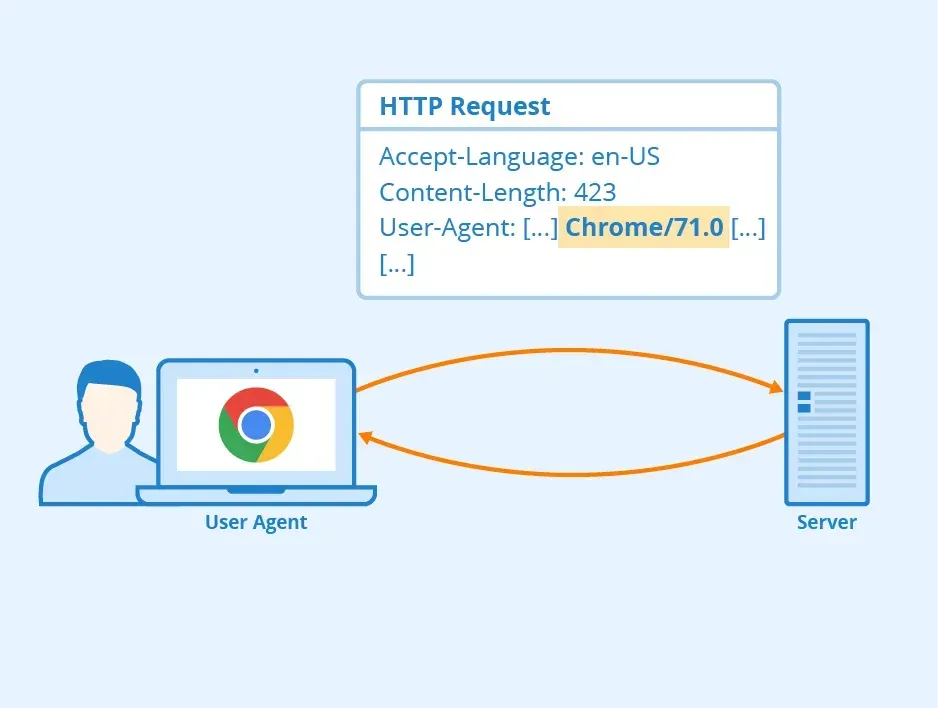
Web Scraper verwenden möglicherweise gefälschte oder ungewöhnliche User-Agent-Strings, um eine Erkennung zu vermeiden, was in Ihren Website-Traffic-Logs als Anomalie erscheinen kann.
Häufige und wiederholte Anfragen von denselben IP-Adressen
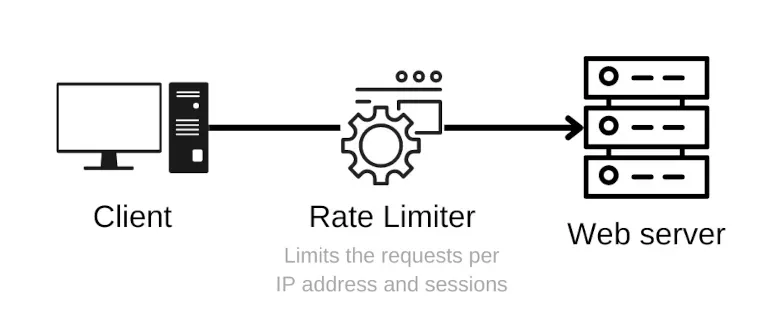
Web Scraper stellen oft mehrere Anfragen von derselben IP-Adresse, was ein Zeichen für unbefugte Web-Scraping-Aktivitäten sein kann. Sie sollten eine Rate-Begrenzung für IP-Adressen erstellen.
Unerklärlicher Anstieg von Seitenaufrufen und Absprungrate
Ein plötzlicher Anstieg von Seitenaufrufen und Absprungrate kann darauf hindeuten, dass ein Web Scraper mehrere Seiten auf Ihrer Website besucht, ohne sich mit dem Inhalt zu beschäftigen, was zu erhöhtem Traffic ohne entsprechende Nutzerinteraktion führt.
Methoden zur Verhinderung von Web Scraping
Implementierung von Ratenbegrenzung

Ratenbegrenzung beschränkt die Anzahl der Anfragen, die innerhalb eines bestimmten Zeitraums an Ihre Website gestellt werden können, und hilft so, übermäßiges Web Scraping zu verhindern. Es gibt verschiedene Strategien zur Ratenbegrenzung:
- IP-basierte Ratenbegrenzung: Begrenzen Sie die Anzahl der Anfragen von einer einzelnen IP-Adresse.
- Benutzerbasierte Ratenbegrenzung: Begrenzen Sie die Anzahl der Anfragen von einem bestimmten Benutzer oder einer Benutzergruppe.
- API-Schlüssel-Ratenbegrenzung: Begrenzen Sie die Anzahl der Anfragen für Benutzer mit einem spezifischen API-Schlüssel.
Einsatz von CAPTCHA und Challenge-Response-Tests
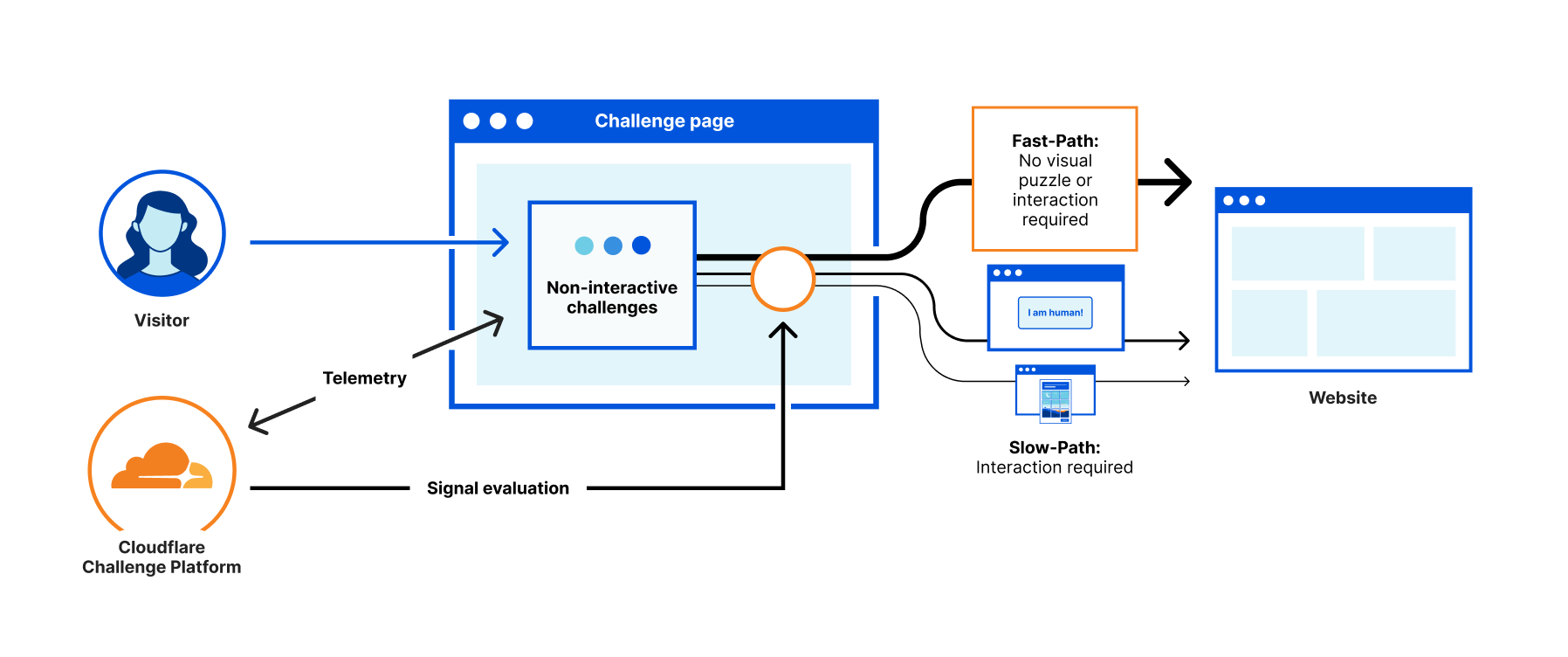
CAPTCHA-Tests helfen dabei, zwischen menschlichen Benutzern und automatisierten Bots zu unterscheiden. Einige beliebte CAPTCHA-Lösungen umfassen:
- Google reCAPTCHA: Verwendet fortgeschrittene Risikoanalysen, um zwischen Bots und Menschen zu unterscheiden.
- Honeypot-Technik: Unsichtbare Formularfelder, die von Bots ausgefüllt, aber von Menschen ignoriert werden.
- Eigene Challenge-Response-Tests: Erstellen Sie eigene Tests, wie einfache Matheaufgaben oder Bilderkennungsaufgaben.
Benutzerregistrierung und -authentifizierung erforderlich machen
Die Anforderung an Benutzer, sich zu registrieren und zu authentifizieren, kann gelegentliche Web Scraper abschrecken. Erwägen Sie Folgendes:
- Social-Media-Login: Ermöglichen Sie Benutzern, sich mit ihren bestehenden Social-Media-Konten anzumelden.
- Zwei-Faktor-Authentifizierung (2FA): Verlangen Sie von Benutzern, eine zusätzliche Verifizierungsebene bereitzustellen, wie z.B. einen Code, der an ihr Mobilgerät gesendet wird, für zusätzliche Sicherheit.
Verschleierung von Website-Inhalten und -Struktur
Das schwieriger Interpretierbar-Machen Ihrer Website-Inhalte und -Struktur kann Web-Scraping-Versuche abschrecken:
- Dynamischer HTML-Inhalt: Verwenden Sie AJAX oder andere Techniken zum dynamischen Laden von Inhalten, um es schwieriger zu machen, den Inhalt Ihrer Website zu parsen.
- JavaScript-Rendering: Rendern Sie Inhalte mit JavaScript, da viele Web Scraper Schwierigkeiten haben, JavaScript-Code auszuführen.
- Verschlüsselte Datenelemente: Verschlüsseln Sie sensible Datenelemente, um es für Scraper schwieriger zu machen, nützliche Informationen zu extrahieren.
Überwachung und Analyse des Webverkehrs
Ein genaues Auge auf den Verkehr Ihrer Website zu haben, kann Ihnen helfen, potenzielle Web-Scraping-Versuche zu identifizieren und darauf zu reagieren:
- Webanalyse-Tools: Verwenden Sie Tools wie Google Analytics, um Verkehrsmuster zu überwachen und potenzielle Web-Scraping-Aktivitäten zu identifizieren.
- Intrusion-Detection-Systeme (IDS): Implementieren Sie IDS, um verdächtige Verkehrsmuster und potenzielle Sicherheitsbedrohungen zu erkennen und darauf zu reagieren.
- Analyse des Benutzerverhaltens: Analysieren Sie das Benutzerverhalten, um Anomalien und potenzielle Web-Scraping-Aktivitäten zu identifizieren.
Auswahl einer Lösung zur Verhinderung von Web Scraping

Merkmale, die bei der Auswahl einer Lösung zur Verhinderung von Web Scraping zu beachten sind
Einfache Integration: Wählen Sie eine Lösung, die leicht in Ihre bestehende Website-Infrastruktur integriert werden kann.
Skalierbarkeit und Flexibilität: Optieren Sie für eine Lösung, die mit den wachsenden Anforderungen Ihrer Website skalieren kann und sich an neue Scraping-Techniken anpasst.
Kosten-Nutzen-Analyse: Bewerten Sie die Kosten der Lösung gegenüber den potenziellen Verlusten durch unbefugtes Web Scraping.
Beispiele für Dienste zur Verhinderung von Web Scraping
Einige Dienste sind auf die Verhinderung von Web Scraping spezialisiert. Beliebte Beispiele sind:
- Cloudflare: Bietet eine Vielzahl von Sicherheitsfunktionen, einschließlich Ratenbegrenzung, Bot-Management und DDoS-Schutz.
- Imperva Incapsula: Bietet eine umfassende Sicherheitslösung, die Anti-Bot-Schutz, Ratenbegrenzung und Optimierung der Website-Leistung umfasst.
- Akamai: Bietet eine Reihe von Sicherheitslösungen, einschließlich Bot-Erkennung und -Minderung, Ratenbegrenzung und Optimierung der Inhaltsauslieferung.
Abwägung zwischen Benutzererfahrung und Sicherheit
Beim Implementieren von Maßnahmen zur Verhinderung von Web Scraping ist es wichtig, Sicherheit mit Benutzererfahrung auszubalancieren. Stellen Sie sicher, dass die ergriffenen Maßnahmen die Fähigkeit legitimer Benutzer, auf Ihre Website zuzugreifen und mit ihr zu interagieren, nicht negativ beeinflussen.
Häufig gestellte Fragen (FAQ)
Ist Web Scraping immer illegal oder unethisch?
Web Scraping ist nicht grundsätzlich illegal oder unethisch, kann es aber werden, wenn es gegen die Nutzungsbedingungen einer Website verstößt, Urheberrechte verletzt oder die Privatsphäre der Nutzer beeinträchtigt. Stellen Sie immer sicher, dass Sie die Erlaubnis haben, eine Website zu scrapen, und dass Sie ethische Richtlinien bei Web-Scraping-Aktivitäten befolgen.
Kann ich Web Scraping auf meiner Website komplett stoppen?
Es ist schwierig, alle Web-Scraping-Versuche zu verhindern, aber die in diesem Blogbeitrag skizzierten Strategien können unbefugtes Scraping erheblich reduzieren.
Bedenken Sie, dass entschlossene Scraper immer noch Wege finden können, Ihre Abwehrmaßnahmen zu umgehen, daher ist es wichtig, den Verkehr Ihrer Website kontinuierlich zu überwachen und Ihre Sicherheitsmaßnahmen zu aktualisieren.
Wie kann ich feststellen, ob meine Website gescrapet wird?
Häufige Anzeichen von Web Scraping sind ein plötzlicher Anstieg der Serverlast und Bandbreitennutzung, ungewöhnliche Muster von User-Agent-Strings, häufige und wiederholte Anfragen von denselben IP-Adressen und ein unerklärlicher Anstieg von Seitenaufrufen und Absprungrate.
Die Überwachung Ihres Website-Traffics mithilfe von Analysetools kann Ihnen helfen, potenzielle Scraping-Aktivitäten zu identifizieren.
Wird die Implementierung von Maßnahmen zur Verhinderung von Web Scraping die Leistung meiner Website beeinflussen?
Einige Maßnahmen zur Verhinderung von Web Scraping können geringfügige Auswirkungen auf die Leistung Ihrer Website haben, aber die Vorteile des Schutzes Ihrer Daten und der Integrität Ihrer Website überwiegen in der Regel etwaige Nachteile.
Bewerten Sie die Abwägung zwischen Sicherheit und Benutzererfahrung bei der Implementierung von Präventionsmaßnahmen.
Kann ich Web-Scraping-Präventionstechniken verwenden, um meine API zu schützen?
Ja, viele der in diesem Blogbeitrag besprochenen Web-Scraping-Präventionstechniken können auch zumSchutz Ihrer API angewendet werden.
Ratenbegrenzung, Authentifizierung und Überwachung der API-Nutzung können helfen, unbefugten Zugriff und übermäßige Datenextraktion zu verhindern.
Was sollte ich tun, wenn ich unbefugtes Web Scraping auf meiner Website entdecke?
Wenn Sie unbefugte Web-Scraping-Aktivitäten auf Ihrer Website feststellen, sollten Sie zunächst die in diesem Blogbeitrag beschriebenen Präventionsmaßnahmen ergreifen. Zusätzlich möchten Sie möglicherweise Rechtsberatung einholen, um Ihre Optionen für Maßnahmen gegen die Verantwortlichen für das unbefugte Scraping zu verstehen.
Fazit
Die Verhinderung von unbefugtem Web Scraping ist entscheidend für den Schutz der Leistung, Daten und des gesamten Benutzererlebnisses Ihrer Website.
Durch das Verständnis von Web-Scraping-Techniken und die Implementierung einer Kombination aus Ratenbegrenzung, CAPTCHA-Tests, Benutzerauthentifizierung, Inhaltsverschleierung und Verkehrsüberwachung können Sie Ihre Website effektiv gegen unbefugte Datenextraktion schützen.
Es ist auch wichtig, eine Web-Scraping-Präventionslösung zu wählen, die Ihren spezifischen Anforderungen entspricht und Sicherheit mit Benutzererfahrung ausbalanciert.
Bleiben Sie über Web-Scraping-Trends informiert und passen Sie Ihre Präventionsstrategien bei Bedarf an, um den langfristigen Schutz Ihrer Website und Daten zu gewährleisten.